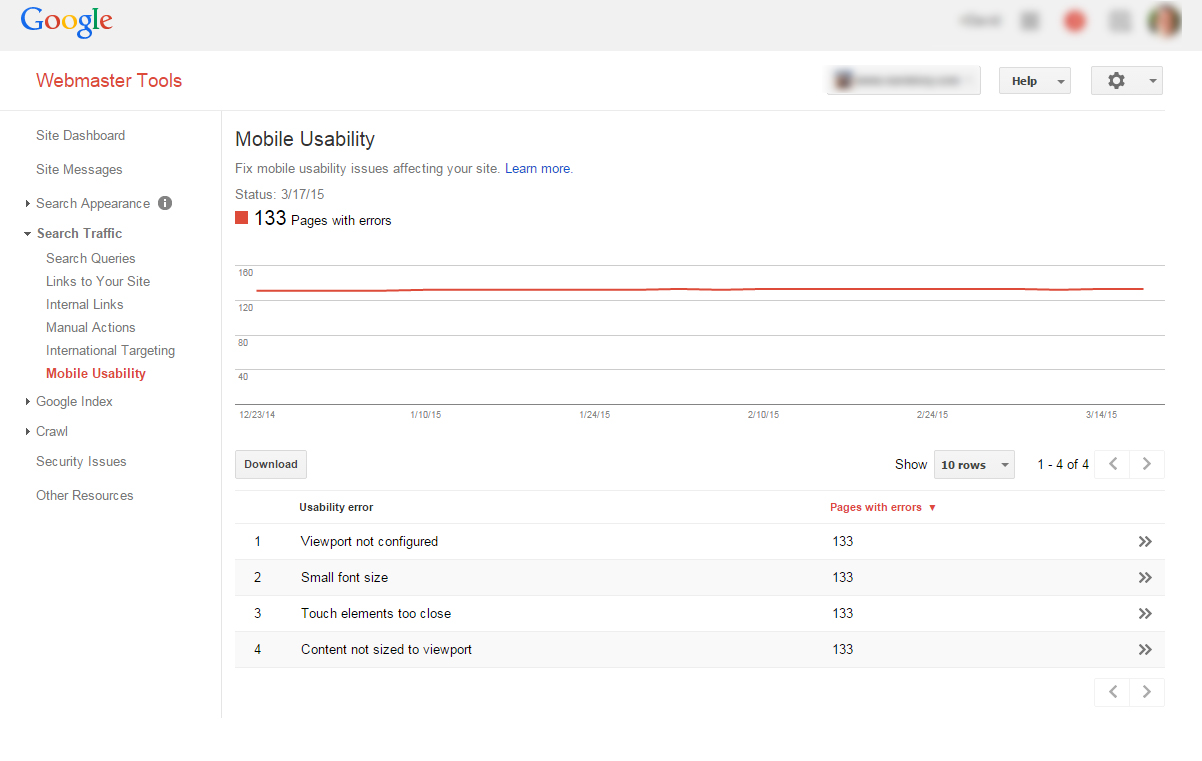
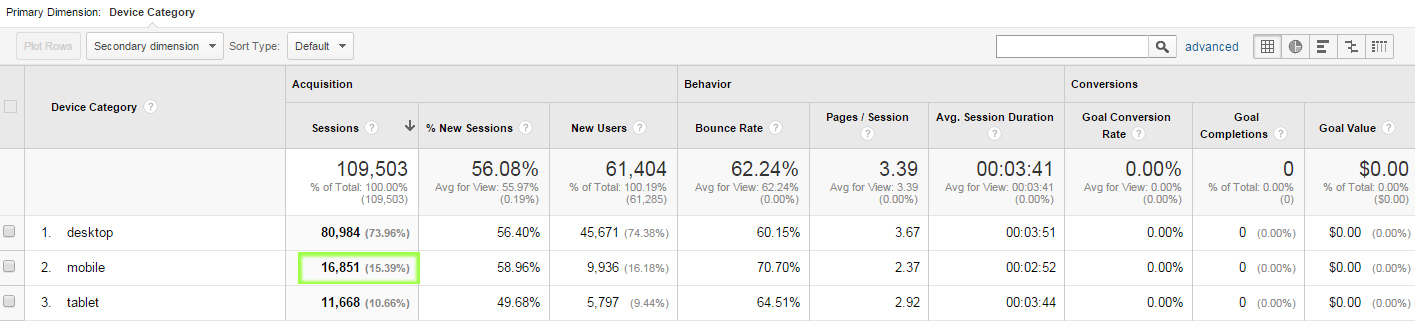
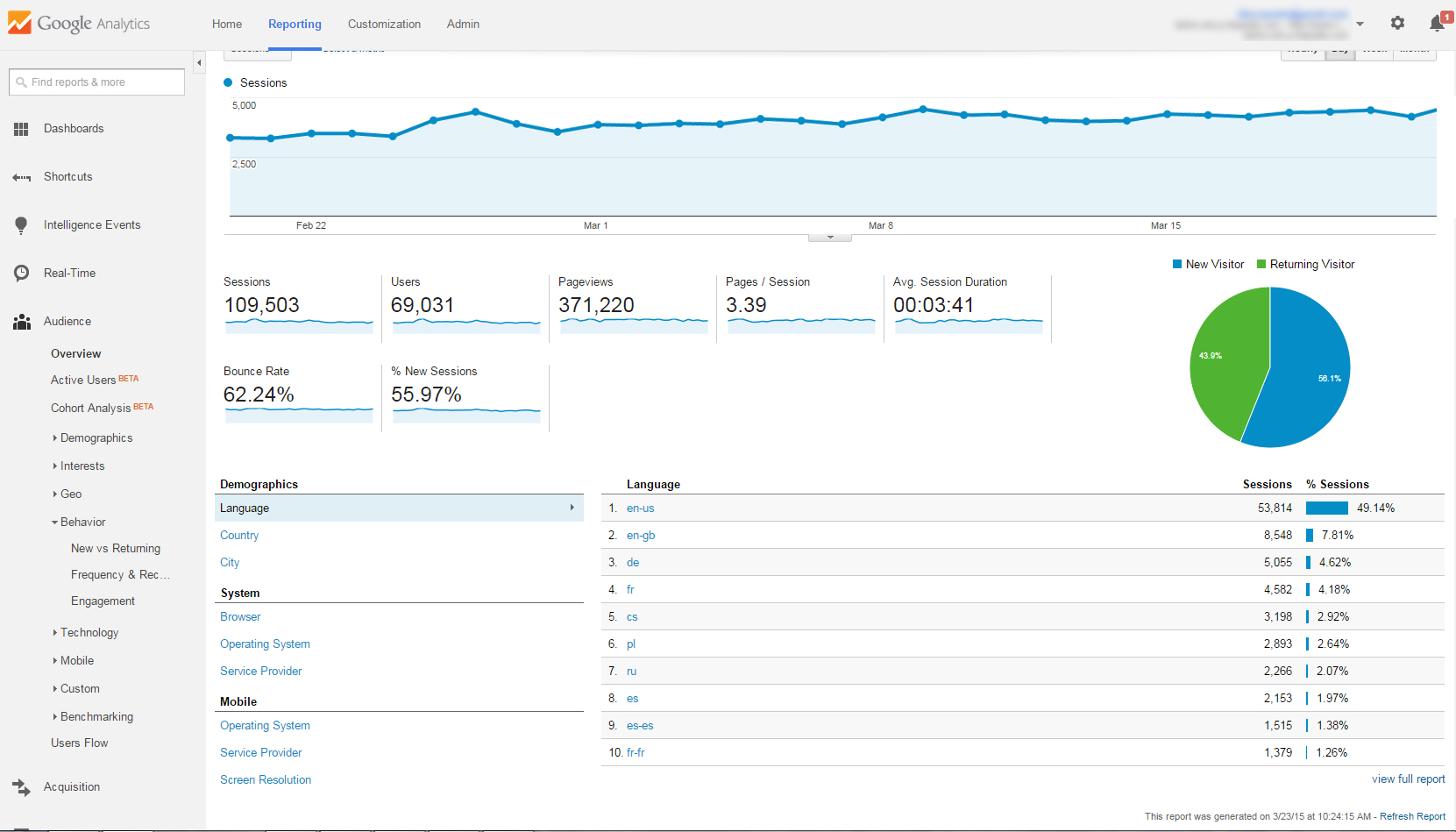
Après une demande de transfert de nom de domaine assortie d’une proposition financière, nous nous sommes plongés dans les affres de l’évaluation monétaire d’un nom de domaine. Nous espérons que cela soit utile à qui sera confronté à ce problème.
Avant toute chose, il faut définir la valeur d’un nom de domaine dans l’absolu.
- Un nom de domaine fraîchement acheté à une valeur basique définie par les frais administratifs de l’ICANN en fonction du TLD, et des marges prises par les revendeurs et hébergeurs (1&1, ovh, gandi, etc…). En général ce prix s’établit sous la barre des 10 euros…
- A cette valeur d’achat initiale ils faut ajouter une valeur sémantique établie en fonction de la concurrence
- Un nom de domaine ancien prends une valeur qu’il faut modérer en fonction du référencement qui a été pratiqué
Pour ce qui concerne les noms de domaine anciens, ils acquièrent un maximum de valeur si :
-Le champ sémantique du site correspond au champ sémantique du nom de domaine
-Le site est resté le même sur une longue période (pas racheté, revendu, refait avec autre contenu…)
-Le référencement est « propre » (au yeux de google). Avant -à l’inverse- d’effectuer un achat, c’est une chose à rappeler…
Un nom de domaine peut créer de la valeur pour son propriétaire en générant des gains liés à l’activité du site s’il est actif. La valeur ajoutée d’un site peut se mesurer à l’aune des investissements (en temps et en valeur fiduciaire) qui ont été faits pour son référencement, mais aussi via des revenus financiers induits, construits sur une popularité et une démarche volontaire (dons et revenus publicitaires type adsense).
Par ailleurs, même si le nom de domaine n’est pas relié à un site Web actif, il peut encore générer des revenus indirects, résultants d’économies de coûts associés à la prévention un cybersquatteur ou concurrent de s’emparer du nom de domaine et des potentialités sémantiques associées.
La propriété d’un nom de domaine confère au propriétaire avec deux types de droits:
Le premier est lié à la flexibilité managériale, puisque le choix lui appartient de développer le site Web associé, ou de capitaliser le nom de domaine pour une période ultérieure. Le second droit est associé au pouvoir des marques. Si le nom de domaine est liés à une marque, le propriétaire reçoit en sus le droit à la protection juridique de cette dernière, qui protège le ou les noms de domaines associés. Le/la propriétaire peut ainsi empêcher quiconque de revendiquer le nom de domaine, si il/elle souhaite exercer ce droit. Les options disponibles pour le propriétaire de la marque varient depuis une action en justice de plein droit pour obtenir l’us d’une nom de domaine, et pleine latitude pour acheter le nom de domaine. Ainsi la valeur du nom de domaine est la résultante des bénéfices attendus et des options générées, souplesse de gestion et bénéfices liés aux marques.
Voici les différentes méthodes que nous avons testé:
Les sites d’évaluation gratuits :
-siteprice.org
-estibot.com
-valuate.com
-siteworthchecker.org
-instica.com
-domainindex.com
-domainvaluecongland.com
-valuegator.net
-urlrate.com
-godaddy.com
-dnsaleprice.com*
-valuemydomain.name
*estimation en fonction du prix de vente de domaines approchants
Utiliser ce type d’évaluation gratuite reste extrêmement problématique.
1-La variabilité des résultats en font une option peu convaincante. Nous avons ainsi pour le même nom de domaine, eu une évaluation supérieure à 10,000 euros, et une autre à 0 euro, la plupart se situant entre 30 et 500 euros.
2-La base d’évaluation reste le plus souvent très superficielle du fait de l’automatisation du process. Sont pris en compte des critères externes mesurables, présents sur le net (ex. audits alexa, etc…) qui se basent sur la popularité (nombre de liens) mais n’examinent à aucun moment leur qualité, l’estimation du trafic SEO à un instant T, l’E-réputation ou le ranking (mentions obtenus sur la requête du NDD), entre autres.
3-D’autres sites proposent une évaluation semi-automatique nécéssitant de disposer déjà de données (traffic, âge, cible, etc). C’est une méthode plus fiable mais plus chronophage.
4-Certains sites ne proposent aucune données sous un certain niveau de trafic (-100 visites/jour par exemple).
5-Certains sites n’envoient les résultats qu’après avoir soumis une adresse mail, qui sera ensuite revendue aux spammeurs et publicitaires de tout poil…
Toutefois, faut de mieux et de temps, une soumission « à la louche » sur ces sites, assorti ensuite d’un calcul moyen permet d’avoir un premier chiffre grossier, qu’il conviendra de préciser en fonction d’autres critères, que l’on peut retrouver (en partie) plus bas.
– La première constatation d’évidence est celle-ci: Un nom de domaine ne vaut rien si personne n’est prêt à l’acheter. S’il est trop éloigné de champs sémantiques intéressants et concurrentiels ou de marques connues, sa valeur diminue d’autant. S’il est court, il aura d’autant plus de valeur. Le SEO a changé, et s’il est intéressant de cultiver les « longue traînes » dans les URL et le contenu interne d’un site, il ne sert plus à rien de disposer d’un nom de domaine également en « longue traîne », Google se basant sur d’autres critères pour évaluer la valeur d’un site. Ce choix repose alors sur une approche marketing.
Quelques pistes toutefois: Le trafic d’un site acquiers de la valeur si le repreneur du nom de domaine compte rester sur cette même thématique. C’est pour cela que les « parkings » de noms de domaine créent un faux site ultra-optimisé dans la même sémantique pour conserver sa valeur SEO autant que faire ce peut. Leur popularité externe ne diminue pas forcément même si le contenu change, du fait de l’immobilisme le plus souvent des pages pointant vers lui. Courant sont en effet les sites ayant des webmasters à l’affût de liens brisés à partir de statistiques, mais bien moins sont ceux qui effectivement suivent les liens pour contrôler la permanence du site, bien que faire un lien sortant vers un site de mauvaise qualité pour google n’apporte rien. Donc même parqués pour des années, bien des sites conservent ce capital de liens.
La méthode d’évaluation longue:
Comme l’a reconnu l’USPAP, il existe trois méthodes généralement admises pour estimer la valeur de tous les actifs:
1-L’approche du marché, destinée à refléter les prix comparatifs du marché;
2-La méthode du revenu destinée à refléter la valeur économique de l’actif;
3-La méthode du coût, qui vise à refléter les caractéristiques d’utilité de l’actif.
Ces approches s’appliquent aux actifs incorporels et aux propriétés intellectuelles, ainsi qu’aux biens corporels.
Chaque méthode d’évaluation met l’accent sur un attribut du nom de domaine. En utilisant ces trois méthodes on peut augmenter la valeur de confiance quand à l’analyse finale. Néanmoins, des valorisations faibles résultent de l’utilisation naïve de ces trois approches. Or c’est souvent l’information disponible pour l’évaluation qui doit déterminer l’approche utilisée.
L’approche du marché examine les caractéristiques comparatives de biens raisonnablement compétitifs. Avec suffisamment de données transactionnelles axées sur le marché à partir de laquelle estimer un nom de domaine comparable, on dispose d’un instrument relativement fiable d’emblée. Dès lors que le nom de domaine à examiner s’éloigne de la compétition, la méthode d’approche du marché s’affaiblit.
L’approche du revenu repose sur le flux de trésorerie que le nom de domaine devrait générer sur sa durée. Cette approche nécessite une estimation raisonnable des flux de trésorerie futurs et leur risque. Ainsi, la qualité de l’évaluation dépend de l’exactitude des estimations utilisées dans le modèle d’évaluation.
La méthode du coût regarde le de reproduction ou de remplacement d’un atout. Cette approche ne est pas appropriée pour les noms de domaine et des actifs incorporels, puisque le coût pour remplacer un tel actif est rarement le reflet de sa valeur, sauf à sa création.
L’approche de marché du nom de domaine pour son l’évaluation tient la fois d’un art et d’une science. L’art provient de la connaissance et de l’expérience pris en compte dans la compréhension des facteurs influant sur la valeur d’un nom de domaine, tandis que l’approche scientifique implique des techniques statistiques pour quantifier l’importance de ces facteurs.
Par exemple, en comparant plusieurs TLDs (extensions) d’un nom de domaine .net/.com/.biz on peut être plus facilement en mesure d’évaluer toute extension. Toutefois dans la réalité la tarification des extensions de noms de domaine se heurtent à deux obstacles majeurs: Pas suffisamment de noms de domaine avec des extensions différentes pour effectuer un ratio fiable, et la relation de prix entre ces différentes extensions peuvent ne pas être un multiple constant vis à vis des unes et des autres.
On peut en revanche utiliser des techniques statistiques pour prédire le prix de noms de domaine comparables fondés sur une base de données fiable des prix de domaine. Un modèle statistique de prédiction est donc bienvenu, et une condition préalable pour effectuer toute évaluation significative.
Les modèles statistiques utilisent la relation entre ces facteurs et les prix des noms de domaine vendus, pour déterminer le prix d’un nom de domaine donné à un moment précis dans le temps. Ces modèles fournissent une méthode « scientifique » pour estimer la valeur d’un NDD sur la base de comparaison.
Les techniques traditionnelles de régression linéaire ne donnent pas de résultats satisfaisants, du fait que la relation entre les prix du marché et les extensions sont plus susceptibles d’être non linéaires. Ces « variables muettes » pour chaque extension ne donnent pas des résultats significatifs. En outre, parce que le marché du nom de domaine est relativement nouveau et pas encore très actif, des techniques statistiques plus solides sont nécessaires.
A la base du modèle statistique se trouvent un ensemble de critères en fonction de la demande de noms de domaine et les prix historiques pratiqués des noms vendus. Le modèle estimé donne le meilleur rapport entre les critères et la valeur spécifiée. Cette relation est utilisée pour prédire le prix de ne importe quel nom de domaine. Il y a environ 10-12 de ces critères quantifiables, comprenant le nombre de requêtes sur Google pour le mot clé incorporé inclus dans le NDD. Ces critères ne prennent pas directement en compte la contribution d’une marque à la valeur d’évaluation, car elle nécessite de nombreux calculs et des données spécifiques à la collection des domaines liés à la marque.
Concernant les base de données d’évaluation pour estimer le modèle prédictif de la valeur, les prix de transaction prélevés dans des ventes aux enchères publiques, les prix des NDD mise sous séquestre et les données d’enchères scellées peuvent être pris en compte. Pour chacune des variables de prédiction, les données sont collectées à partir de sources accessibles au public au moment de la vente.
L’approche du revenu est généralement utilisée pour prédire le bénéfice potentiel de référence d’un site web dans l’évaluation des sites Web actifs et les noms de domaine liés à des marques. Cette approche par le résultat d’une évaluation, ou Discounted Cash Flow (DCF), est l’un des outils utilisés pour évaluer un actif de manière général, mais qui peut s’appliquer aux NDDs; Les revenus représentent les flux de trésorerie supplémentaires ou incrémentielle que le nom de domaine devrait générer au propriétaire sur la durée de son utilisation.
L’analyse DCF nécessite l’accès à des informations sur la circulation, les revenus et les coûts associés à l’entreprise. Pour utiliser cet outil d’évaluation puissant il doit être supposé que le nom de domaine génère des revenus issus de son trafic. La force de cette approche est qu’elle peut être appliquée à tout NDD indépendamment du fait que le site est actif ou non.
Le modèle d’affaires des revenus du trafic se concentre sur les noms de domaine générant des clics, via des liens d’annonceurs. Cela fonctionne donc si le pay-per-click (PPC) est connu pour un champ sémantique donnée. La disponibilité de cette information, en général publique, reste fiable sur des recherches de mots clés et revenus de publicité.
Ces avantages sont fondés sur les points suivants:
1. Le prix catalogue des annonces de vente médian est d’environ 400 euros alors que seul un petit nombre de ventes sont dans des ordres de grandeur supérieurs, allant jusqu’à dizaines de milliers d’euros. Du fait de ce seuil, les estimations produites seront moins fiables en raison de la rareté des données.
2. Pour un niveau spécifique de trafic, l’extension des recettes sur d’autres extensions restent pertinent, combiné avec d’autres facteurs constants. Toutefois, les données des ventes suggère que les .com commandent toujours le trafic, même après ajustement pour la composition de mot-clé.
3. Seule une petite fraction des noms de domaine vendus on un trait d’union. Ils sont sous-évalués dans le modèle statistique.
Toutefois: Les prix historiques du marché, en particulier ceux issus de ventes aux enchères, souffrent d’un marché de l’offre et de la demande asynchrone, de sorte qu’avant la fin de l’enchère tout les acheteurs potentiels ne se sont pas manifestés. Le prix de vente peut donc ne pas refléter fidèlement la volonté de payer pour ce nom de domaine.
5. L’approche du revenu permet de prendre en compte plusieurs scénarios, comme le « meilleur des cas, » le « pire des cas », et le « cas standard ». Cette analyse donne une image plus intuitive de la gamme des valeurs de marché possibles.
1. Le regroupement de noms de domaine en dépôt-vente comparables sont fondés sur des données historiques mais implique des erreurs de classification considérable, en particulier dans des clusters n’ayant que quelques données sur les ventes.
2. Les courtiers ont tendance à conserver les informations liées à leur chiffre d’affaires. Cette diminution de transparence et de vérifiabilité des évaluations tend donc à réduire la fiabilité de ce critère.
En revanche, ni l’approche du marché, ni la technique DCF ne capte la valeur des options de flexibilité. Il y a aussi la composante marque-option qui peut être faussée en considérant l’action d’un cybersquatteur (généralement en contrefaçon de marque). En fait, même si un nom de domaine n’a pas de marque associée, aussi longtemps que ce nom de domaine peut être rattaché à une marque ou déposé comme marque, il possède une valeur plus élevée qu’un nom de domaine issus de termes génériques. Plus la valeur d’une marque augmente, de même plus augmente la valeur du nom de domaine associé. La bonne utilisation de ces critères peut ainsi permettre d’obtenir ne serait-ce qu’une fourchette de base de négociation lors d’un transfert.
La méthode d’évaluation longue (extraits) est traduite et adaptée de l’anglais – Src: domainmart.com